


As the volume of data grows, so has the means of storing this data. First, there was the data warehouse, which stores only relational or structured data. Many companies still use data warehouses to get data for cross-functional reporting and end-user analysis. But as unstructured data began to increase—think of all the customer email communications or video footage that makes up 80 to 90% of all information in an organization—and newer technologies such as artificial intelligence (AI) and machine learning emerged, businesses realized they needed another form of data storage. Thus, the data lake was born. The data lake has since become a centralized target for all the data that lands in an organization. Once the data enters the data lake, some basic processing happens, the data gets summarized and often copied over into a data warehouse where it’s modeled with structured tables, governance rules, and traditional tools on top.
These two systems are difficult to manage—and painful. Worse, they create data silos. You end up with incompatible data security models. Despite the inconvenience, many businesses use a hybrid architecture—data warehouses for business analytics and data lakes for data science and machine learning.
So, it’s little wonder that when Microsoft unveiled the data lakehouse (called OneLake) in Microsoft Fabric, their unified analytics platform, the IT and data community were excited.
Hailed as the “OneDrive for all your data, Arun Ulag, Microsoft’s corporate VP for Azure Data noted, “There’s literally hundreds — if not thousands — of products and open source technologies and solutions that customers have to make sense of.” And a lot of those data and analytics products tend to keep their data in silos. “When I talk to customers, one of the messages I hear consistently is that they’re tired of paying this integration tax,” he said.
While it’s tempting to integrate the data lakehouse into your existing data solution as it’s now officially “a thing,” it’s worth examining how it’s different or going to augment the data solutions you currently have.
Data Lakehouse: The Best of Both Worlds
A data lakehouse bridges the gap between lakes and warehouses — combining the affordable, flexible storage of a data lake with the data management and governance of a warehouse. It brings together the best features of data warehouses and data lakes while overcoming their limitations. This makes it faster and easier for businesses to draw insights from all of their data, regardless of format or volume.
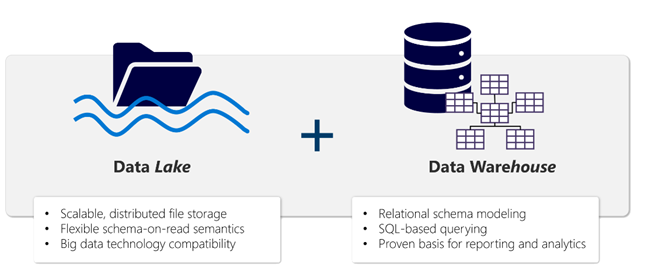
It lets data engineers, data scientists, and data analysts to access and use data all in one place. It also:
- Uses Spark and SQL engines to process large-scale data and support machine learning or predictive modeling analytics
- Organizes data in a schema-on-read format, which means you define the schema as needed rather than having a predefined schema
- Supports ACID (Atomicity, Consistency, Isolation, Durability) transactions through Delta Lake formatted tables for data consistency and integrity
As data architecture continues to evolve and as newer forms of data storage and compute like the lakehouse surface, you may be wondering if your business could benefit from them? For any business, managing data— and getting value from all that information—is a constant challenge. However, these three questions will help you make a more informed decision before you transition to a data lakehouse.
1. How will your business benefit from a data lakehouse?
There’s a lot of information about how lakehouses benefit your data. But your business? Data lakehouses can make a real impact on your bottom-line as they break down silos and increase operational efficiency—key concerns for IT and business leaders. Currently, many businesses use several point solutions to manage their growing customer data that require substantial investment.
Data lakehouses, on the other hand, offer the best of data warehouses and data lakes, helping you reduce costs and developer backlogs and do more with less. By separating computing and storage, they allow you to add more storage. By separating computing and storage, they allow you to add more storage without increasing computing power, providing a cost-effective way to expand data analytics efforts while keeping data storage expenses low.
When adopting the lakehouse architecture, you can decentralize data storage and processing depending on your organization’s structure and business needs. Here are three common approaches:
- Each business unit builds its own lakehouse for its goals whether it’s product development, customer acquisition or customer support.
- Each functional area builds its own lakehouse to optimize operations within its business area.
- Some organizations create a new lakehouse for strategic initiatives or unforeseen events to drive fast, decisive action.
The unified lakehouse architecture enables data architects to build simpler data architectures that meet business needs without complex orchestration of data movement across siloed data stacks for BI, DS, and ML. Plus, the openness of the architecture helps you leverage the ecosystem of open technologies without getting locked in. And since lakehouses are usually built on separate, scalable cloud storage, multiple teams can easily access each lakehouse.
2. Will my data be secure and compliant?
For many IT and business leaders, data governance and security is a top concern. Lakehouses address this by adding a management interface on top of data lake storage, providing a standardized way to manage access control, data quality, and compliance across the organization. They support fine-grained (row, column, and view level) access control via SQL, query auditing, attribute-based access control, data versioning, and data quality constraints and monitoring. These features utilize standard interfaces familiar to database administrators (for example, SQL GRANT commands), allowing more of your staff to manage all the data in the organization uniformly. Centralizing all the data in a lakehouse with a single data management interface also reduces the administrative burden and errors that come with managing different systems.
3. How do data lakehouses compare with data warehouses in terms of performance and cost?
In other words, are lakehouses worth it? Just going by the encouraging feedback for the Microsoft Fabric lakehouse, the answer is a resounding “yes.” Data lakehouses are built around separate, elastically scaling compute and storage to minimize operational costs while maximizing performance. Modern systems provide comparable or even better performance per dollar to traditional data warehouses for SQL workloads, using the same optimization techniques inside their engines (e.g., query compilation and storage layout optimizations). Plus, lakehouses leverage cost-saving features from cloud providers, such as spot instance pricing, which allows the system to handle the loss of worker nodes mid-query, and lower prices for infrequently accessed storage—benefits that traditional data warehouse engines typically do not support.
Unlike data warehouses, data lakehouses are inexpensive to scale because integrating new data sources is automated—you don’t have to manually fit them into prevailing data formats and schema. They are also “open,” meaning the data can be queried from anywhere using any tool, rather than being limited to only applications that can handle structured data (such as SQL).
Until recently, the combined data lake and data warehouse model was the only option for organizations who wished to continue with legacy BI and data analytics workflows while also migrating towards smart, automated data initiatives. But that’s about to change as the popularity of the lakehouse continues to grow.
How to Get Started
On the data maturity curve, different companies exist on different points. No matter where you are on your data journey, our data experts would love to help you unlock your data potential with the right solution and technology. If you would like a data lakehouse tour to see how it can help your organization break down silos and unlock efficiency, contact us today.


