

By Sal Cardozo, Senior Vice President, Data Analytics & AI
Data drives modern businesses. But what drives data? How does data housed in various places flow from one system to another and land at its destination? The short answer: data pipelines. Think of data pipelines as the nerves of the data ecosystem transporting data around. Building them up — and building them right — ensures your data flows freely through various filters, apps, and APIs, ultimately settling at its final destination in a form you can use.
That is why data pipelines are critical: they eliminate most manual steps, automate, and simplify data flow.
Benefits of Data Pipelines:
- Centralized data collection and storage
- Improved reporting and analytics
- Reduced load on backend systems
- Enhanced data quality and compliance
Building Data Pipelines: Best Practices
1. Consider Five Key Elements
Five critical elements go into building data pipelines. Don’t overlook them.
Data sources
Data comes from sources, including any system or software that generates data for your business. Common data sources include application APIs, the cloud, relational databases, and NoSQL.
Acquisition
Also known as ingestion, this stage integrates the data from multiple sources into the pipeline. Depending on your platform, you can design pipelines that support both batch and streaming pipelines.
In batch ingestion, data is periodically collected and stored based on predetermined schedules set by developers and analysts. Stream processing is another method where the pipeline collects, transforms, and loads data quickly in real-time.
Processing
Once the data is ingested, it must be transformed into actionable information. At this stage of the pipeline, you would validate, clean up, normalize, and transform your data into insights.
There are two standard data integration methods to choose from: Extract, Transform, Load (ETL) and ELT Extract, Load, Transform (ELT). The integration method you choose will determine your data pipeline architecture.
Destination
After the data is processed, it arrives at a centralized location that houses all the modified and cleaned data. Typically, a data warehouse, a data lake, or a data lakehouse where the data is either stored in on-premises systems or the cloud.
From here, the data is consumed for reporting, business intelligence, or other purposes.
Workflow
Your workflow outlines the structure of tasks and processes within the data pipeline, including dependencies. A workflow orchestration tool like Azure Data Factory can make all the difference.
2. Define Your Pipeline Architecture
What framework should you choose?
Before diving into implementation, it’s crucial to define the architecture of your data pipeline.
It’s important to ask yourself if you will choose the ETL or ELT framework for data integration.
What you choose, ETL or ELT, changes your entire data pipeline design since the two major processes — loading and transformation — get interchanged.
Let’s examine the pros and cons of both frameworks.
ETL
In the ETL process, data is extracted and transformed before it’s loaded into storage. Most businesses depend on ETL for:
-
- Faster analysis: Since the data is transformed and structured before being loaded, the data queries are handled more efficiently, allowing for faster data analysis.
-
- Better compliance: Organizations can comply with privacy regulations by masking and encrypting data before it’s loaded into storage.
-
- Cloud and on-premise environments: ETL can be implemented in data pipelines that rely on cloud-based and on-premise systems.
Despite its merits, companies are moving away from ETL because of its slow loading speeds and the constant modifications to accommodate schema changes, new queries, and analyses. It’s not suited for large volumes of data and data sources but is ideal for smaller data sets that require complex transformation or in-depth analysis.
ELT
In the ELT process, the data is extracted and loaded into data lakes before it’s transformed. Ideal for:
-
- Automation: Teams can standardize data models and automate them
- Faster loading: The ELT framework loads data and provides instant access to the information
-
- Flexible data format: It supports structured and unstructured data and can ingest data in any format
-
- High data availability: If you’re using business intelligence platforms or analytic tools that don’t require structured data, they can instantly collect and act on data from the data lake
-
- Easy implementation: It can work with existing cloud services or warehouse resources, easing implementation roadblocks and saving money
-
- Scalability: Since most ELT pipelines are cloud-based, you can easily scale your data management systems. Modifying pipelines on the cloud is faster, cheaper, and less labor-intensive than the physical on-premise changes required to scale an ETL pipeline
Perhaps the only downside of using ELT is that analysis with ETL might be slower when handling large volumes of data since the transformations are applied after all the data is loaded.
3. Orchestrate Data with Azure Data Factory
Enterprises have different types of data located in disparate sources — on-premise, in the cloud, structured, unstructured, and semi-structured — all arriving at different intervals and speeds.
The first step in building an information production system is to connect to all the required sources of data and processing, such as software-as-a-service (SaaS) services, databases, file shares, and FTP web services. Then, move the data to a centralized location for processing.
Azure Data Factory, a cloud service for orchestrating events in a logical progression using “pipelines,” lets you move data, call events, send notifications, look up data, and even call other pipelines. It can all be done in sequence, loops, or parallel, depending on actions within the pipeline.
Without Azure Data Factory, enterprises must build custom data movement components or write custom services to integrate these data sources and processing, which is expensive and complicated to integrate and maintain. Moreover, they lack the enterprise-grade monitoring, alerting, and controls a fully managed service can offer.
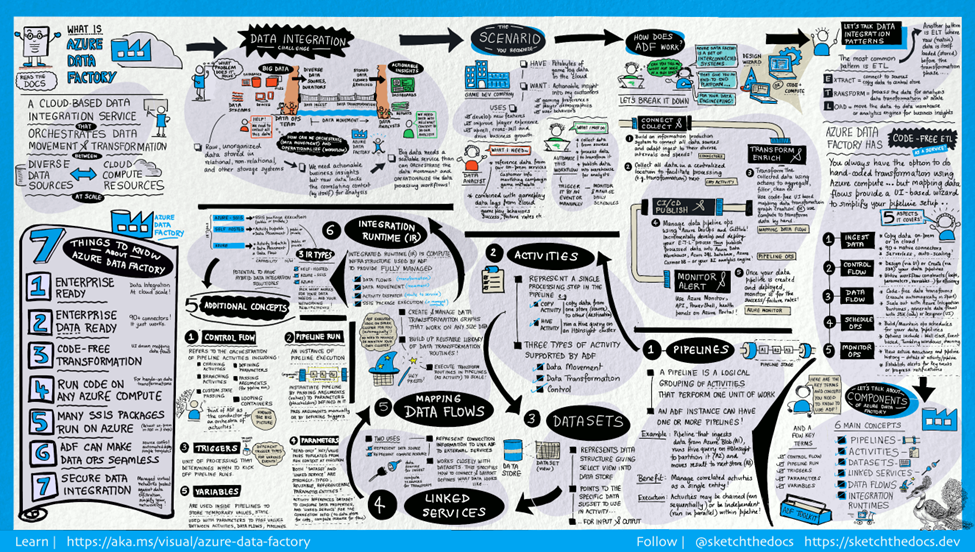
Benefits of Pipelines in Azure Data Factory
There are many benefits of using Azure Data Factory for a cloud-based data repository:
- Integration with the Azure platform provides a direct link to Data Fabric, Databricks Lakehouse, SQL Server, and Synapse Lake database
- Pipeline triggers, either by schedule or a file being updated
- Parallel execution using Azure Data Factory’s powerful “for-each loop” features
- Scalability and extensibility to data sets of all sizes
- Alerts and logging sent to Azure Log Analytics for operational management
- Deployments via Azure’s DevOps platform
4. Document and Test
Document and test your data pipeline thoroughly. Outline your data pipeline design, assumptions, dependencies, limitations, and performance clearly and concisely. You should also test your data pipeline at different levels, such as unit testing for individual components, integration testing for the whole pipeline, and end-to-end testing for the final output. Automate the testing wherever you can to reduce time and effort and get the best results.
5. Monitor and Manage Pipelines
Lastly, monitoring and managing data pipelines ensures their reliability and performance. After successfully building and deploying your data integration pipeline, monitor the pipelines. Azure Data Factory has built-in support for pipeline monitoring via Azure Monitor, API, PowerShell, Azure Monitor logs, and health panels on the Azure portal.
Building efficient data pipelines on Azure requires careful planning, architecture design, and the right set of services. How effectively data pipelines move data depends on how they’re engineered. Less efficient pipelines will increase your data stack costs and require data engineers to do more work. By following the best practices above, you can increase the value of your data assets, and stay focused on what matters most: delivering insights and business value.
If you’d like to build an effective data pipeline with Azure Data Factory, get in touch with us. We can help simplify your data and its management, reduce cost and complexity, and accelerate business value.


