
A Sneak Peek Into the Future of Data Science and Technology
By Santiago Silvestrini, Senior Manager, Data Analytics & AI
Synthetic data refers to data that is artificially generated using algorithms, simulations, or models to represent real-world data. This data is designed to look and behave like real data, but it is not sourced from actual individuals or events. Synthetic data is often used as a substitute for real data when the real data cannot be used due to privacy or security concerns, or when the real data is not available.
The term was first coined in 2013 at the Massachusetts Institute of Technology by Kalyan Veeramachaneni, principal investigator of the Data to AI (DAI) Lab and a principal research scientist in MIT’s Laboratory for Information and Decision Systems. Back then, his team was tasked to analyze data from the popular online learning platform edX and they wanted to bring in some students to help.
The problem?
The data was too sensitive and, thus, they were not allowed to share it with this group.
To overcome this restriction, they created a new set of data with the premise that it must “feel” and “taste” like real data—so any processes, models, or analysis developed using it can be later applied to the real data with similar results.
This, of course, begs the question: What does it mean for data to “feel” and “taste” like real data?
The primary difference between synthetic data and fake or mock data is that the former captures the relationships, the patterns, and the statistical properties of the original data, while the latter is randomly generated data or simply dummy data created to replicate a particular business scenario. The ability to artificially generate a set of data replicating the inner properties of the original data offers a range of benefits, including improved privacy and security, better data quality, and the ability to test and develop new systems and applications.
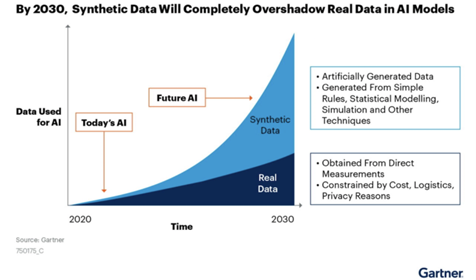
Synthetic data generation has been growing in popularity and it is set to play a significant role in the future of data science and technology: According to Gartner, by 2024 sixty percent of the data used for the development of AI and Analytics projects will be synthetically generated, potentially overtaking real data in AI Models by 2030.
Use Cases and Applications
Possessing a set of data that shares the statistical properties and captures the patterns and relationships of the original data while protecting confidentiality and privacy opens the door to a broad set of applications in many industries from insurance, healthcare, software development, and beyond.
Here are a few examples:
- Data Sharing. Data sharing is not only an essential business capability but a crucial component of digital transformation as well.
One of the main challenges when sharing data—even within the same organization—is compliance with privacy policies and laws. By using synthetic data, businesses can maintain the privacy of individuals while still benefiting from the insights and information that data analysis can provide, as it is exempt from the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act.
Many companies are already adopting this approach, setting up cross-border synthetic data lakes colleagues across the organization can use as a self-service data center without compromising privacy or security, allowing data to flow freely, and empowering data-driven decision-making.
Sharing your data with academia and the ever-growing community of data enthusiasts will enable your organization to power up innovation and creativity. Data Scientists are eager to put their hands on real data—in fact, most of the open datasets available are frequently obfuscated, anonymized, or limited in terms of features and variables available. Using synthetic data in datathons/hackathons will encourage creative problem-solving and experimentation, with the non-trivial additional benefit of being able to later implement and reproduce any analysis, models, or insights produced by the participants over your real data.
- Improve Fraud Detection Models. Fraudulent transactions are—hopefully!—a tiny fraction of your data. Nevertheless, the economic impact of detecting fraud can be huge for businesses—not only due to the potential damage caused to your brand but also because the cost associated with investigating a potential fraud can be up to twenty-four thousand dollars for a single customer. So, it’s not just about rooting out potential fraudulent transactions, but also making sure that the flagged transactions are fraudulent—to, in other words, reduce the false-positive rate.
Scenarios in which we have imbalances in our data can affect the most sophisticated algorithms’ ability to detect rare or new fraudulent techniques. By using Synthetic Data generation to amplify or exaggerate fraudulent transactions—a technique known as up-sampling—will help machine learning models to better detect these cases, improving the accuracy and sensitivity of your models. In this context, we can say that Synthetic Data is even better than the original data!
- Remove Bias. Synthetic data can be used to mitigate the effects of bias in real data by generating data that is representative of minority groups. In many cases, real data for minority groups is limited, making it difficult to train AI models to accurately represent these groups. By improving the accuracy of AI models for minority groups, synthetic data can help to ensure that these groups are not unfairly disadvantaged and that their perspectives and needs are accurately represented.
According to Gartner, by 2022 eighty-five percent of algorithms will be erroneous due to bias. By making AI more representative and fairer, we can help to foster a more inclusive society.
- Software Developing & Testing. Synthetic data is used to test software and systems before they are released, allowing developers to identify and fix potential issues before they cause harm.
Generating Synthetic Data
There are several techniques used to generate synthetic data, each approach dependent upon the specific needs and requirements—size and complexity of the data; desired level of accuracy; the need for privacy protection—of the task at hand.
Some examples are:
- Statistical simulation. This method involves using statistical models to simulate the distribution and relationships of variables in the actual data. Common methods include random sampling from a statistical distribution, bootstrapping, and Monte Carlo simulation.
- Generative models. This method involves training machine learning models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), to generate synthetic data that closely resembles the actual data.
- Rule-based algorithms. This method involves defining rules and algorithms to generate synthetic data based on relationships and patterns in the real data. Common methods include decision trees, clustering algorithms, and k-nearest neighbors.
- Synthetic Overlaying Technique (SOT). This method involves overlaying synthetic data on top of real data to preserve the structure and relationships in the real data while removing sensitive information.
- Data perturbation: This method involves making small changes to the real data to generate synthetic data while preserving the overall structure and relationships in the data. Common methods include adding random noise, swapping values, or adding missing data.
Finding the Right Model
Generating synthetic data is a complex process that requires a deep understanding of statistics, data science, and data generation methods.
It’s important to choose the right method, model the data accurately, and validate the synthetic data to ensure it is representative and useful.
In a nutshell, this process is comprised by the following steps:
- Define the data structure. Determine the structure of the synthetic data, including the number of columns (variables), the types of variables (numeric, categorical, etcetera), and the distribution of values for each variable.
- Choose a method. Decide on the method to be used to generate synthetic data. Common methods include statistical simulation, generative models, and rule-based algorithms.
- Model the data. Develop a model that captures the relationships and patterns in the real data. This step involves choosing the appropriate statistical distribution, defining the relationships between variables, and parameterizing the model.
- Generate the data: Use the model to generate synthetic data. This may involve sampling from the model, generating values based on the relationships and patterns defined in the model, or combining multiple models to create a complete data set.
- Validate the data: Verify that the synthetic data accurately represents the real data by checking for consistency, accuracy, and representativeness. This may involve comparing the synthetic data to real data, testing the synthetic data in applications, or evaluating the performance of models trained on the synthetic data.
- Refine the model: Repeat the process as necessary to refine the model and generate more accurate and representative synthetic data.
Ready to Get More Value Out Of Your Data?
When it comes to data migration, data strategy, data management consulting, and data services, we’re here to help ignite your success. Our certified consultants have hands-on experience with Microsoft on-premise solutions, hybrid data landscapes, Azure, and AWS data analytics services.
For more information, download our data analytics ebook, The Secret to Understanding & Leveraging Data Democratization, or reach out to speak with an OZ expert today.


